Oops! Something went wrong while submitting the form.
No credit card required
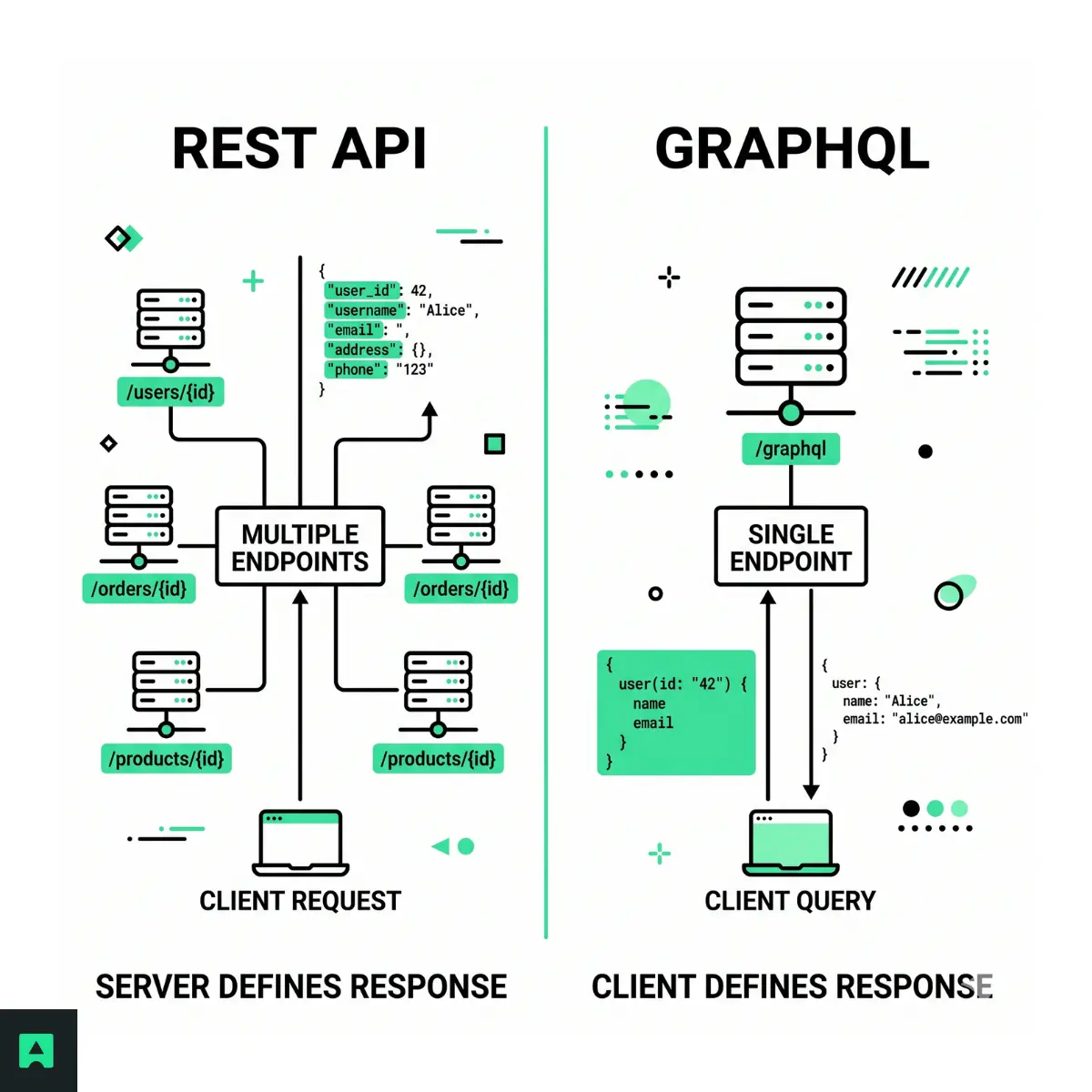
When you're deciding between GraphQL vs REST, you're not just picking a data format or a library — you're choosing how your frontend teams will query data, how your backend will evolve, and how much operational complexity you're willing to carry. Both are types of web API that solve the same fundamental problem: how a client communicates with a server to get data. But they solve it differently.
REST organizes your API around resources and exposes multiple endpoints — one per resource type. The server defines what each response looks like. GraphQL exposes a single endpoint and lets the client specify exactly the fields it needs, across multiple related resources, in one request. The server validates that query against a schema and returns only what was asked for.
The right choice between GraphQL and REST depends on the complexity of your data model, the diversity of your clients, your caching requirements, your team's experience, and how fast your product is evolving. This guide breaks down the core differences, compares performance and caching trade-offs, and gives you a clear framework for deciding when to use each — or both.
TL;DR
Use REST when you want simplicity, standard HTTP semantics, and strong native caching.
Use GraphQL when clients need flexible queries and nested data in fewer requests.
Use both when your frontend needs flexible queries but your backend services are already stable as REST.
GraphQL vs REST: the core difference
REST is built around resources. Each resource — a user, an order, a product — has its own endpoint, and the server decides what the response looks like. A GET /users/42 call returns whatever the server was built to return, even if the client only needs the user's name and email.
GraphQL flips that model. There is typically one endpoint, and the client sends a query describing exactly which fields it needs — potentially across multiple related resources at once. The server validates the query against a schema and returns only what was asked for.
Neither approach automatically wins. REST is simpler to get started with and benefits from decades of tooling and HTTP semantics. GraphQL is more powerful for complex, frontend-driven data needs but comes with more operational overhead. The right choice depends on what you're building and who's consuming your API.
Resource-based: each resource has a dedicated URL (/users, /orders/99, /products/7)
Uses HTTP verbs: GET to read, POST to create, PUT/PATCH to update, DELETE to remove
Stateless: each request contains all the information the server needs; no session state
Cacheable: GET responses can be cached natively by browsers, CDNs, and proxies
Standardized: built on well-understood HTTP semantics that any developer can follow
A typical REST interaction looks like this:
# Read a user
GET /users/42
# Create an order
POST /orders
Content-Type: application/json
{
"userId": 42,
"productId": 7,
"quantity": 2
}
# Update a product
PATCH /products/7
Content-Type: application/json
{
"price": 29.99
}
REST is well-suited to systems where resources map cleanly to URLs, where caching matters, and where you want public-facing APIs that any client can consume without specialized tooling.
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries, developed by Facebook and open-sourced in 2015. Rather than defining a fixed response structure per endpoint, GraphQL lets clients declare exactly what data they need.
Key characteristics of GraphQL
Schema-driven: every type and field is defined in a strongly typed schema
Single endpoint: typically /graphql — all operations go through one URL
Client specifies fields: the query controls what data is returned, not the server
Supports queries (read), mutations (write), and subscriptions (real-time)
Arguments at any level: fields can accept arguments at any depth of the query, not just in the URL or query string as in REST
A basic GraphQL query looks like this:
# Fetch a user and their recent orders in one request
query {
user(id: 42) {
name
email
orders(last: 5) {
id
status
product {
name
price
}
}
}
}
GraphQL is well-suited to applications where multiple clients need different projections of the same data, where nested relationships are common, and where frontend teams want control over data fetching without waiting on backend changes.
GraphQL vs REST: side-by-side comparison
Feature
REST
GraphQL
API shape
Resource-based; response structure defined by server
Schema-driven; response structure defined by client query
Endpoint model
Multiple endpoints (/users, /orders, /products)
Single endpoint (typically /graphql)
Data fetching
Server decides what fields are returned
Client specifies exactly the fields it needs
Overfetching / underfetching
Common — server returns fixed response shapes
Avoided — client requests only what it needs
Caching
Native HTTP caching (GET requests, CDN-friendly)
Requires custom caching strategies; no native GET-based cache
Versioning
Common practice: /v1/, /v2/ endpoints
Schema evolution with deprecations; no versioning explosion
Error handling
Standard HTTP status codes (404, 500, etc.)
Usually returns 200; errors inside response body
Tooling
Mature ecosystem: Postman, curl, OpenAPI/Swagger
Growing ecosystem: Apollo, GraphiQL, Relay
Learning curve
Lower — well-understood HTTP semantics
Steeper — schema, resolvers, query language
Performance
Depends on endpoint design; multiple round trips possible
Fewer round trips; N+1 query risk with poor resolver design
Security
Standard auth headers, rate limiting per endpoint
Rate limiting more complex; query depth/cost analysis needed
Best use cases
Public APIs, CRUD services, simple resource models
Frontend-heavy apps, mobile clients, complex data graphs
GraphQL vs REST performance
Performance is one of the most misunderstood areas of the GraphQL vs REST debate. GraphQL is often described as "faster" because it reduces overfetching and can retrieve nested data in a single request. That's true in some scenarios — but it's not a guaranteed win.
Where GraphQL has a performance advantage
In REST, fetching a user's profile, their recent orders, and each order's product details requires multiple sequential requests:
GET /users/42
GET /users/42/orders
GET /products/101
GET /products/204
GET /products/389
GraphQL collapses all of that into one query:
query {
user(id: 42) {
name
email
orders(last: 5) {
id
status
product {
name
price
}
}
}
}
On high-latency connections — mobile networks especially — eliminating those extra round trips makes a real difference.
Where REST can outperform GraphQL
REST GET requests are cacheable at the HTTP layer. Browsers, CDNs, and reverse proxies handle this transparently — no application-level code required. GraphQL queries are typically POST requests, which are not cached natively. Unless you implement a persistent query layer or a caching middleware like Apollo Server's response cache, every GraphQL request hits your resolvers.
Additionally, poorly designed GraphQL resolvers can cause the N+1 query problem: fetching a list of 10 orders triggers 10 separate product lookups. Solving this requires batching tools like DataLoader, which adds implementation complexity. REST endpoints can be optimized with JOIN queries at the database level and are not exposed to this pattern by default.
The bottom line on performance
GraphQL is not inherently faster than REST. Performance depends on resolver design, caching strategy, query complexity, batching, and backend architecture. GraphQL gives you more control over data fetching — but that control comes with responsibility. Optimize your resolvers, implement DataLoader, and add a response caching layer before drawing conclusions about which is faster for your use case.
GraphQL vs REST caching
Caching is one of the clearest practical differences between the two approaches — and it favors REST out of the box.
REST caching
REST APIs are built on HTTP semantics, which includes a mature and well-understood caching model. GET requests are idempotent and cacheable. Browsers cache responses automatically, CDNs like Cloudflare or Fastly serve them at the edge, and reverse proxies work without any special configuration.
HTTP headers like Cache-Control, ETag, and Last-Modified work natively
CDN caching of GET endpoints requires zero application-level code
Public REST APIs benefit from cache layers at every hop in the network
GraphQL caching
GraphQL's single endpoint and POST-based requests break the native HTTP caching model. Every query is different, so you can't cache at the URL level. Common strategies to work around this:
Persisted queries: hash a known query and send GET requests with the hash — CDN-cacheable
Apollo response cache: cache full query results server-side with configurable TTL per field
Client-side normalized cache: Apollo Client and Relay maintain entity-level caches tied to IDs
HTTP GET for queries: the GraphQL spec allows GET requests for read queries, which some implementations support
These strategies work well but require deliberate design and implementation effort. If your application relies heavily on CDN or edge caching, REST will get you there faster with less infrastructure overhead.
When to use REST
REST is the right choice when simplicity, cacheability, and standard HTTP semantics matter more than query flexibility. Consider REST when:
You're building a public API — REST is easier for third-party developers to consume without specialized tooling or client libraries
Your application is CRUD-heavy — Create, Read, Update, Delete CRUD operations map naturally to HTTP verbs and resource endpoints
You need HTTP caching — GET endpoints cache natively at the CDN or browser level without additional infrastructure
Your data model is relatively flat — resources don't have deeply nested relationships that force multiple round trips
Your team is more familiar with REST — lower learning curve means faster delivery and fewer operational surprises
You're building integrations or webhooks — REST endpoints are straightforward for external systems to consume
Practical example: a public product catalog API for an e-commerce platform. Products, categories, and inventory are well-defined resources. Clients can cache product listings at the CDN. Partners integrate with standard HTTP calls. No GraphQL schema or client library needed. REST is the obvious fit:
GET /products?category=electronics&limit=20
GET /products/42
GET /categories/5/products
If you're starting from scratch, Abstract's guide to building a REST API walks through the full setup.
When to use GraphQL
GraphQL earns its complexity premium in scenarios where different clients need different data shapes, or where deeply nested data would require too many REST round trips. Consider GraphQL when:
Your app is frontend-heavy — product teams need to iterate fast without waiting on new backend endpoints for every UI change
You have multiple clients with different data needs — a mobile app and a web dashboard might need very different fields from the same underlying data
Bandwidth matters — mobile clients benefit from requesting only the fields they actually display
Your data has complex nested relationships — orders with products, reviews, sellers, and shipping status, for example
Your UI evolves rapidly — new screens and data requirements can be served without adding endpoints
You want a self-documenting API — the GraphQL schema serves as living documentation of your data model
Practical example: a dashboard that shows a user's account summary, recent activity, billing status, and personalized recommendations. Each widget needs a different slice of data. With REST, you'd either over-fetch with a bloated endpoint or make 4–5 separate calls. With GraphQL, one query covers all of it:
query DashboardData {
user(id: 42) {
name
accountStatus
recentActivity(limit: 10) {
type
timestamp
description
}
billing {
plan
nextRenewal
amountDue
}
recommendations {
productId
title
reason
}
}
}
Pros and cons
REST pros
Simpler mental model — resources, URLs, and HTTP verbs are universally understood
Mature tooling — Postman, curl, OpenAPI/Swagger, and virtually every HTTP client work out of the box
Native HTTP semantics — status codes, headers, and caching behave as expected
Straightforward caching — GET requests cache natively at browser, proxy, and CDN layers
Easier public API adoption — no specialized client library required for consumers
REST cons
Overfetching is common — endpoints return fixed shapes, even when clients only need a subset of fields
Multiple round trips — fetching related resources requires multiple requests unless you build custom aggregation endpoints
Versioning can get messy — evolving a public REST API often means maintaining /v1/ and /v2/ in parallel indefinitely
Less flexible for complex UIs — data requirements that don't map to resource boundaries require endpoint proliferation or bloated responses
GraphQL pros
Exact data fetching — clients get precisely what they asked for, nothing more
Fewer round trips for nested data — related data can be fetched in a single query
Schema-driven and self-documenting — the schema is both the contract and the documentation
Easier evolution without version explosion — fields can be deprecated without breaking existing clients
Flexible for multiple clients — web and mobile apps request different field sets from the same API
GraphQL cons
More setup and operational complexity — schema design, resolvers, and tooling require more upfront investment
Harder caching out of the box — POST-based queries break native HTTP caching
Performance pitfalls if resolvers are poorly designed — N+1 queries can degrade performance without DataLoader
More complex observability and rate limiting — tracking usage per field or per query requires specialized tooling
Steeper learning curve — teams unfamiliar with schemas, resolvers, and the query language will need time to ramp up
Can GraphQL and REST work together?
Yes — and in production systems, this is often the most pragmatic approach. GraphQL and REST are not mutually exclusive. Many teams use them together strategically, letting each do what it does best.
GraphQL as a gateway over REST microservices
A common pattern is to keep your existing backend microservices as REST APIs and add a GraphQL layer that aggregates them. The GraphQL server calls your users service, orders service, and billing service over REST internally, then exposes a unified schema to the frontend.
Here's what that looks like in practice:
# Existing backend — stays as REST
GET https://api.internal/users/42 → { id, name, email, ... }
GET https://api.internal/orders?user=42 → [{ id, status, productId, ... }]
GET https://api.internal/billing/42 → { plan, amountDue, nextRenewal }
// GraphQL layer aggregates the REST services into one schema
const resolvers = {
Query: {
user: async (_, { id }) => {
const res = await fetch(`https://api.internal/users/${id}`);
return res.json();
},
orders: async (_, { userId }) => {
const res = await fetch(`https://api.internal/orders?user=${userId}`);
return res.json();
},
billing: async (_, { userId }) => {
const res = await fetch(`https://api.internal/billing/${userId}`);
return res.json();
}
}
};
# Frontend consumes a single GraphQL query instead of three REST calls
query {
user(id: 42) { name email }
orders(userId: 42) { id status }
billing(userId: 42) { plan amountDue }
}
Clients get the flexibility of GraphQL queries. Your backend services stay stable as REST. No full rewrite required.
REST for public APIs, GraphQL for internal consumption
Many teams maintain a public REST API for partners and third-party integrations — familiar, well-documented, easy to consume — while using a GraphQL API internally for frontend consumption where iteration speed matters more.
Gradual GraphQL adoption
You don't have to replace your entire REST stack to adopt GraphQL. Start with a single resource, add a schema layer on top, and expand incrementally. Existing REST endpoints remain in place and continue serving their consumers while you introduce GraphQL where it adds the most value.
Frequently Asked Questions
What is the main difference between GraphQL and REST?
REST uses multiple endpoints, each returning a fixed response shape tied to a specific resource. GraphQL exposes a single endpoint where the client specifies exactly which fields it needs, so the server returns only that data, nothing more, nothing less.
What are overfetching and underfetching, and does GraphQL solve them?
Overfetching means a REST endpoint returns more data than the client needs; underfetching means it returns too little, forcing additional requests. GraphQL solves both because clients declare the exact fields they want in a single query, eliminating wasted bandwidth and extra round trips.
When should you use GraphQL instead of REST?
GraphQL is a strong fit when multiple clients (web, mobile, third-party) have different data needs, when deeply nested relationships would require many REST round trips, or when bandwidth matters (for example, on mobile networks). It is less suitable for simple CRUD services where the added complexity outweighs the benefits.
Does GraphQL support HTTP caching the same way REST does?
No. REST responses map to URLs, so browsers and CDNs can cache them natively using standard HTTP mechanisms. GraphQL typically uses a single POST endpoint, which breaks URL-based caching. Teams usually work around this with persisted queries, response-level caches, or tools like Apollo Client's normalized cache.
What is the N+1 problem in GraphQL and how do you fix it?
The N+1 problem occurs when a GraphQL resolver fires a separate database query for each item in a list: one query to fetch 10 users, then 10 more queries to fetch each user's posts. The standard fix is batching with a tool like DataLoader, which groups those individual lookups into a single query.
Can you use GraphQL and REST together in the same project?
Yes. A common hybrid pattern is to place a GraphQL gateway in front of existing REST microservices. The gateway presents a unified schema to clients while delegating to REST endpoints behind the scenes. This lets teams adopt GraphQL incrementally without rewriting every service at once.
Conclusion
The GraphQL vs REST decision comes down to what you're optimizing for. If your priority is simplicity, cacheability, and standard HTTP semantics — especially for public-facing or CRUD-heavy APIs — REST is the cleaner choice. If you're building a frontend-heavy application where different clients need different data, nested relationships are common, and overfetching is a real bottleneck, GraphQL is worth the added complexity.
In practice, the two approaches coexist more often than they compete. GraphQL works well as a flexible query layer over stable REST microservices, letting you improve frontend data fetching without rebuilding your entire backend. Neither architecture is a silver bullet — the right API design is the one that fits your team's skills, your clients' needs, and your system's operational constraints.
REST is built around resources. Each resource — a user, an order, a product — has its own endpoint, and the server decides what the response looks like. A GET /users/42 call returns whatever the server was built to return, even if the client only needs the user's name and email.
GraphQL flips that model. There is typically one endpoint, and the client sends a query describing exactly which fields it needs — potentially across multiple related resources at once. The server validates the query against a schema and returns only what was asked for.
Neither approach automatically wins. REST is simpler to get started with and benefits from decades of tooling and HTTP semantics. GraphQL is more powerful for complex, frontend-driven data needs but comes with more operational overhead. The right choice depends on what you're building and who's consuming your API.
Resource-based: each resource has a dedicated URL (/users, /orders/99, /products/7)
Uses HTTP verbs: GET to read, POST to create, PUT/PATCH to update, DELETE to remove
Stateless: each request contains all the information the server needs; no session state
Cacheable: GET responses can be cached natively by browsers, CDNs, and proxies
Standardized: built on well-understood HTTP semantics that any developer can follow
A typical REST interaction looks like this:
# Read a user
GET /users/42
# Create an order
POST /orders
Content-Type: application/json
{
"userId": 42,
"productId": 7,
"quantity": 2
}
# Update a product
PATCH /products/7
Content-Type: application/json
{
"price": 29.99
}
REST is well-suited to systems where resources map cleanly to URLs, where caching matters, and where you want public-facing APIs that any client can consume without specialized tooling.
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries, developed by Facebook and open-sourced in 2015. Rather than defining a fixed response structure per endpoint, GraphQL lets clients declare exactly what data they need.
Key characteristics of GraphQL
Schema-driven: every type and field is defined in a strongly typed schema
Single endpoint: typically /graphql — all operations go through one URL
Client specifies fields: the query controls what data is returned, not the server
Supports queries (read), mutations (write), and subscriptions (real-time)
Arguments at any level: fields can accept arguments at any depth of the query, not just in the URL or query string as in REST
A basic GraphQL query looks like this:
# Fetch a user and their recent orders in one request
query {
user(id: 42) {
name
email
orders(last: 5) {
id
status
product {
name
price
}
}
}
}
GraphQL is well-suited to applications where multiple clients need different projections of the same data, where nested relationships are common, and where frontend teams want control over data fetching without waiting on backend changes.
GraphQL vs REST: side-by-side comparison
Feature
REST
GraphQL
API shape
Resource-based; response structure defined by server
Schema-driven; response structure defined by client query
Endpoint model
Multiple endpoints (/users, /orders, /products)
Single endpoint (typically /graphql)
Data fetching
Server decides what fields are returned
Client specifies exactly the fields it needs
Overfetching / underfetching
Common — server returns fixed response shapes
Avoided — client requests only what it needs
Caching
Native HTTP caching (GET requests, CDN-friendly)
Requires custom caching strategies; no native GET-based cache
Versioning
Common practice: /v1/, /v2/ endpoints
Schema evolution with deprecations; no versioning explosion
Error handling
Standard HTTP status codes (404, 500, etc.)
Usually returns 200; errors inside response body
Tooling
Mature ecosystem: Postman, curl, OpenAPI/Swagger
Growing ecosystem: Apollo, GraphiQL, Relay
Learning curve
Lower — well-understood HTTP semantics
Steeper — schema, resolvers, query language
Performance
Depends on endpoint design; multiple round trips possible
Fewer round trips; N+1 query risk with poor resolver design
Security
Standard auth headers, rate limiting per endpoint
Rate limiting more complex; query depth/cost analysis needed
Best use cases
Public APIs, CRUD services, simple resource models
Frontend-heavy apps, mobile clients, complex data graphs
GraphQL vs REST performance
Performance is one of the most misunderstood areas of the GraphQL vs REST debate. GraphQL is often described as "faster" because it reduces overfetching and can retrieve nested data in a single request. That's true in some scenarios — but it's not a guaranteed win.
Where GraphQL has a performance advantage
In REST, fetching a user's profile, their recent orders, and each order's product details requires multiple sequential requests:
GET /users/42
GET /users/42/orders
GET /products/101
GET /products/204
GET /products/389
GraphQL collapses all of that into one query:
query {
user(id: 42) {
name
email
orders(last: 5) {
id
status
product {
name
price
}
}
}
}
On high-latency connections — mobile networks especially — eliminating those extra round trips makes a real difference.
Where REST can outperform GraphQL
REST GET requests are cacheable at the HTTP layer. Browsers, CDNs, and reverse proxies handle this transparently — no application-level code required. GraphQL queries are typically POST requests, which are not cached natively. Unless you implement a persistent query layer or a caching middleware like Apollo Server's response cache, every GraphQL request hits your resolvers.
Additionally, poorly designed GraphQL resolvers can cause the N+1 query problem: fetching a list of 10 orders triggers 10 separate product lookups. Solving this requires batching tools like DataLoader, which adds implementation complexity. REST endpoints can be optimized with JOIN queries at the database level and are not exposed to this pattern by default.
The bottom line on performance
GraphQL is not inherently faster than REST. Performance depends on resolver design, caching strategy, query complexity, batching, and backend architecture. GraphQL gives you more control over data fetching — but that control comes with responsibility. Optimize your resolvers, implement DataLoader, and add a response caching layer before drawing conclusions about which is faster for your use case.
GraphQL vs REST caching
Caching is one of the clearest practical differences between the two approaches — and it favors REST out of the box.
REST caching
REST APIs are built on HTTP semantics, which includes a mature and well-understood caching model. GET requests are idempotent and cacheable. Browsers cache responses automatically, CDNs like Cloudflare or Fastly serve them at the edge, and reverse proxies work without any special configuration.
HTTP headers like Cache-Control, ETag, and Last-Modified work natively
CDN caching of GET endpoints requires zero application-level code
Public REST APIs benefit from cache layers at every hop in the network
GraphQL caching
GraphQL's single endpoint and POST-based requests break the native HTTP caching model. Every query is different, so you can't cache at the URL level. Common strategies to work around this:
Persisted queries: hash a known query and send GET requests with the hash — CDN-cacheable
Apollo response cache: cache full query results server-side with configurable TTL per field
Client-side normalized cache: Apollo Client and Relay maintain entity-level caches tied to IDs
HTTP GET for queries: the GraphQL spec allows GET requests for read queries, which some implementations support
These strategies work well but require deliberate design and implementation effort. If your application relies heavily on CDN or edge caching, REST will get you there faster with less infrastructure overhead.
When to use REST
REST is the right choice when simplicity, cacheability, and standard HTTP semantics matter more than query flexibility. Consider REST when:
You're building a public API — REST is easier for third-party developers to consume without specialized tooling or client libraries
Your application is CRUD-heavy — Create, Read, Update, Delete CRUD operations map naturally to HTTP verbs and resource endpoints
You need HTTP caching — GET endpoints cache natively at the CDN or browser level without additional infrastructure
Your data model is relatively flat — resources don't have deeply nested relationships that force multiple round trips
Your team is more familiar with REST — lower learning curve means faster delivery and fewer operational surprises
You're building integrations or webhooks — REST endpoints are straightforward for external systems to consume
Practical example: a public product catalog API for an e-commerce platform. Products, categories, and inventory are well-defined resources. Clients can cache product listings at the CDN. Partners integrate with standard HTTP calls. No GraphQL schema or client library needed. REST is the obvious fit:
GET /products?category=electronics&limit=20
GET /products/42
GET /categories/5/products
If you're starting from scratch, Abstract's guide to building a REST API walks through the full setup.
When to use GraphQL
GraphQL earns its complexity premium in scenarios where different clients need different data shapes, or where deeply nested data would require too many REST round trips. Consider GraphQL when:
Your app is frontend-heavy — product teams need to iterate fast without waiting on new backend endpoints for every UI change
You have multiple clients with different data needs — a mobile app and a web dashboard might need very different fields from the same underlying data
Bandwidth matters — mobile clients benefit from requesting only the fields they actually display
Your data has complex nested relationships — orders with products, reviews, sellers, and shipping status, for example
Your UI evolves rapidly — new screens and data requirements can be served without adding endpoints
You want a self-documenting API — the GraphQL schema serves as living documentation of your data model
Practical example: a dashboard that shows a user's account summary, recent activity, billing status, and personalized recommendations. Each widget needs a different slice of data. With REST, you'd either over-fetch with a bloated endpoint or make 4–5 separate calls. With GraphQL, one query covers all of it:
query DashboardData {
user(id: 42) {
name
accountStatus
recentActivity(limit: 10) {
type
timestamp
description
}
billing {
plan
nextRenewal
amountDue
}
recommendations {
productId
title
reason
}
}
}
Pros and cons
REST pros
Simpler mental model — resources, URLs, and HTTP verbs are universally understood
Mature tooling — Postman, curl, OpenAPI/Swagger, and virtually every HTTP client work out of the box
Native HTTP semantics — status codes, headers, and caching behave as expected
Straightforward caching — GET requests cache natively at browser, proxy, and CDN layers
Easier public API adoption — no specialized client library required for consumers
REST cons
Overfetching is common — endpoints return fixed shapes, even when clients only need a subset of fields
Multiple round trips — fetching related resources requires multiple requests unless you build custom aggregation endpoints
Versioning can get messy — evolving a public REST API often means maintaining /v1/ and /v2/ in parallel indefinitely
Less flexible for complex UIs — data requirements that don't map to resource boundaries require endpoint proliferation or bloated responses
GraphQL pros
Exact data fetching — clients get precisely what they asked for, nothing more
Fewer round trips for nested data — related data can be fetched in a single query
Schema-driven and self-documenting — the schema is both the contract and the documentation
Easier evolution without version explosion — fields can be deprecated without breaking existing clients
Flexible for multiple clients — web and mobile apps request different field sets from the same API
GraphQL cons
More setup and operational complexity — schema design, resolvers, and tooling require more upfront investment
Harder caching out of the box — POST-based queries break native HTTP caching
Performance pitfalls if resolvers are poorly designed — N+1 queries can degrade performance without DataLoader
More complex observability and rate limiting — tracking usage per field or per query requires specialized tooling
Steeper learning curve — teams unfamiliar with schemas, resolvers, and the query language will need time to ramp up
Can GraphQL and REST work together?
Yes — and in production systems, this is often the most pragmatic approach. GraphQL and REST are not mutually exclusive. Many teams use them together strategically, letting each do what it does best.
GraphQL as a gateway over REST microservices
A common pattern is to keep your existing backend microservices as REST APIs and add a GraphQL layer that aggregates them. The GraphQL server calls your users service, orders service, and billing service over REST internally, then exposes a unified schema to the frontend.
Here's what that looks like in practice:
# Existing backend — stays as REST
GET https://api.internal/users/42 → { id, name, email, ... }
GET https://api.internal/orders?user=42 → [{ id, status, productId, ... }]
GET https://api.internal/billing/42 → { plan, amountDue, nextRenewal }
// GraphQL layer aggregates the REST services into one schema
const resolvers = {
Query: {
user: async (_, { id }) => {
const res = await fetch(`https://api.internal/users/${id}`);
return res.json();
},
orders: async (_, { userId }) => {
const res = await fetch(`https://api.internal/orders?user=${userId}`);
return res.json();
},
billing: async (_, { userId }) => {
const res = await fetch(`https://api.internal/billing/${userId}`);
return res.json();
}
}
};
# Frontend consumes a single GraphQL query instead of three REST calls
query {
user(id: 42) { name email }
orders(userId: 42) { id status }
billing(userId: 42) { plan amountDue }
}
Clients get the flexibility of GraphQL queries. Your backend services stay stable as REST. No full rewrite required.
REST for public APIs, GraphQL for internal consumption
Many teams maintain a public REST API for partners and third-party integrations — familiar, well-documented, easy to consume — while using a GraphQL API internally for frontend consumption where iteration speed matters more.
Gradual GraphQL adoption
You don't have to replace your entire REST stack to adopt GraphQL. Start with a single resource, add a schema layer on top, and expand incrementally. Existing REST endpoints remain in place and continue serving their consumers while you introduce GraphQL where it adds the most value.
Frequently asked questions
Is GraphQL better than REST?
Neither is universally better. GraphQL excels when you need flexible, client-driven queries and have complex nested data. REST excels when you want simplicity, strong HTTP caching, and predictable resource-based APIs. The best choice depends on your use case, your team, and your clients.
What is the main difference between GraphQL and REST?
REST uses multiple endpoints with server-defined response shapes. GraphQL uses a single endpoint where the client specifies exactly which fields it needs. This gives GraphQL clients more control over data fetching but adds schema and resolver complexity on the backend.
Is GraphQL faster than REST?
Not automatically. GraphQL can reduce round trips and overfetching, which helps on high-latency connections. But it loses native HTTP caching, and poorly designed resolvers can trigger N+1 database queries. Performance depends heavily on implementation quality on both sides.
Which is easier to cache: GraphQL or REST?
REST is significantly easier to cache. GET requests use native HTTP caching supported by browsers, CDNs, and proxies out of the box. GraphQL typically uses POST requests, which are not natively cacheable — you need persisted queries, a response cache layer, or client-side normalized caches.
Can GraphQL replace REST?
GraphQL can replace REST for internal APIs, but it rarely makes sense to replace public REST APIs entirely. REST is more accessible to external consumers and benefits from native HTTP tooling. Most teams that adopt GraphQL use it as a flexible layer on top of existing REST services rather than a full replacement.
Should I use GraphQL for a simple CRUD API?
Probably not. For a straightforward CRUD service — a to-do app, a basic inventory manager, a simple user management system — REST is faster to build, easier to maintain, and doesn't require the schema-and-resolver overhead that GraphQL adds. GraphQL's value shows up when data relationships and client diversity get complex.
Conclusion
The GraphQL vs REST decision comes down to what you're optimizing for. If your priority is simplicity, cacheability, and standard HTTP semantics — especially for public-facing or CRUD-heavy APIs — REST is the cleaner choice. If you're building a frontend-heavy application where different clients need different data, nested relationships are common, and overfetching is a real bottleneck, GraphQL is worth the added complexity.
In practice, the two approaches coexist more often than they compete. GraphQL works well as a flexible query layer over stable REST microservices, letting you improve frontend data fetching without rebuilding your entire backend. Neither architecture is a silver bullet — the right API design is the one that fits your team's skills, your clients' needs, and your system's operational constraints.