

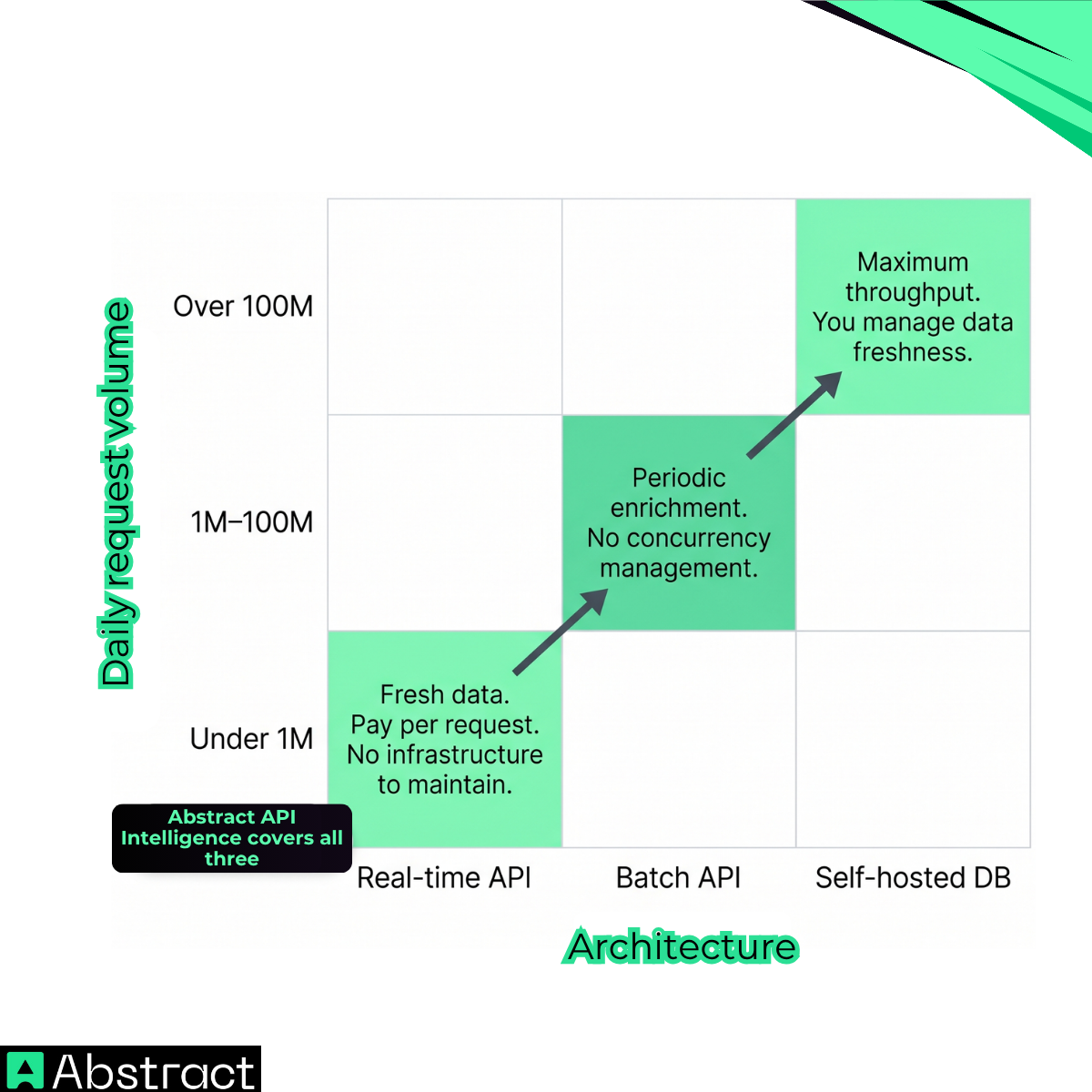
The Three Architectures
The right architecture depends on one input: how many lookups per day. Every other variable — freshness requirements, operational cost, latency tolerance — follows from that.
Real-time API per request
Best for low to medium volume: under roughly 1 million lookups per day. You send one IP, you get one enriched response. No database to maintain, no ETL pipeline, no staleness window to manage. You pay per request, and the data is current.
The tradeoff: latency adds up. At 50ms per request, a million IPs takes around 14 hours single-threaded. Concurrency closes that gap significantly (more on this below), but the per-request model still has a ceiling. For workloads above 1 million per day, the economics and throughput both push toward batch.
Bulk batch endpoint
Best for periodic jobs: daily log enrichment, weekly list cleanup, one-time dataset tagging. You submit a CSV or JSON list, the API processes it asynchronously, and you retrieve the enriched output when it's ready. No concurrency management on your end, no retry logic to write.
The tradeoff: you're working with a processing queue, not a real-time response. If your use case requires enriching IPs as they arrive — fraud scoring at login, content licensing at the CDN edge, real-time risk assessment — batch doesn't fit. It's designed for workloads where a lag of minutes to hours is acceptable.
Self-hosted database
Best for very high volume: over 100 million lookups per day, or environments where latency must be sub-millisecond and network calls aren't acceptable. You license a copy of the IP database, load it locally, and query it in-process.
The tradeoff is significant: you're now responsible for update cadence. Most self-hosted databases refresh every one to seven days. For VPN and proxy data especially, that staleness matters. A residential proxy network can spin up and tear down thousands of IP ranges in hours. A seven-day-old VPN list is not a VPN list — it's a historical record.
| Volume | Architecture | Freshness | Operational cost |
|---|---|---|---|
| Under 1M / day | Real-time API |
Real-time | Low |
| 1M–100M / day | Batch API |
Minutes to hours | Low |
| Over 100M / day | Self-hosted DB |
Days | High |
Rate Limits and How to Work Within Them
Read the response headers
Most IP APIs return rate limit state in the response headers. Abstract IP Intelligence returns:
X-RateLimit-Limit: 1000
X-RateLimit-Remaining: 847
X-RateLimit-Reset: 1714000000
Parse these before you build any retry logic. If X-RateLimit-Remaining hits zero, sleep until the reset timestamp rather than retrying immediately. Here's a minimal header-aware wrapper:
import time
def get_wait_time(headers: dict) -> float:
remaining = int(headers.get("X-RateLimit-Remaining", 1))
reset_ts = int(headers.get("X-RateLimit-Reset", 0))
if remaining == 0 and reset_ts:
return max(reset_ts - time.time(), 0) + 1
return 0
Exponential backoff with jitter
When you receive a 429, don't retry immediately. Add jitter to prevent synchronized retry storms across parallel workers:
import random
def backoff_wait(attempt: int):
wait = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait)
At attempt 0, you wait roughly 1 second. At attempt 4, roughly 17 seconds. Five retries covers most transient rate limit windows without burning through your request allowance.
Size concurrency to your rate limit
More threads isn't always faster. If your plan allows 500 requests per second and each request takes 50ms, the theoretical maximum useful concurrency is 25 threads (500 RPS × 0.05s). Beyond that, you're queuing requests that will hit rate limits before they're sent.
RPS_LIMIT = 500
AVG_LATENCY_S = 0.05
CONCURRENCY = int(RPS_LIMIT * AVG_LATENCY_S) # 25
Start at this number and tune from observed throughput, not from instinct.
Cache aggressively
Most real workloads have significant IP repetition. A web application might log thousands of requests from the same 200 active users in a day. An LRU cache with a one-hour TTL often cuts total request volume by 40 to 60 percent with no accuracy cost:
from functools import lru_cache
@lru_cache(maxsize=10_000)
def cached_lookup(ip: str) -> dict:
return lookup_ip(ip)
For longer-running jobs, replace lru_cache with an explicit TTL cache (cachetools or a Redis-backed store) to prevent stale entries from persisting across the cache window.
Which Fields You Actually Need
Country and city
Standard. Useful for compliance (GDPR jurisdictional logging), content licensing, and fraud heatmaps. Almost every IP data provider covers country-level data reliably, so this field rarely differentiates providers.
ASN and ISP
More important than most teams expect. ASN data tells you whether a request comes from a residential ISP, a cloud provider, a mobile carrier, or a known hosting range. Filtering on ASN is often cheaper and more reliable than any risk score for blocking datacenter traffic or identifying mobile users. A request from AS14618 (Amazon) behaves differently from one from a residential Comcast range, regardless of what the IP's risk score says.
VPN, proxy, and Tor flags
The most expensive signal to maintain and the one where cheap providers fail most visibly. VPN and proxy infrastructure changes daily. A provider relying on a weekly database refresh will miss most active residential proxy networks. Look for providers that update these flags continuously and expose them as discrete boolean fields rather than folding everything into a single score.
Abstract IP Intelligence returns is_vpn, is_proxy, is_tor, and is_hosting as separate fields, so you can set independent thresholds per use case: blocking Tor exits entirely, flagging VPN traffic for step-up authentication, or treating hosting-range traffic differently from residential.
Risk score
A composite signal that combines ASN type, VPN/proxy flags, connection type, and abuse history into a single numeric value. Useful when you want a single threshold for routing decisions rather than writing conditional logic across five fields.
Example Abstract IP Intelligence response (abbreviated):
{
"ip_address": "198.51.100.42",
"country": "United States",
"country_code": "US",
"city": "Ashburn",
"asn": "AS14618",
"isp": "Amazon.com, Inc.",
"connection_type": "hosting",
"is_vpn": false,
"is_proxy": false,
"is_tor": false,
"is_hosting": true,
"risk_score": 72
}
A risk score of 72 on a hosting ASN with is_hosting: true is a clear signal to flag for review. The same score from a residential ISP with no VPN flags means something different. The discrete fields let you build that logic rather than treating the score as a black box.
Reference Implementations
Python: end-to-end batch script
Reads a CSV of IPs, deduplicates, enriches with concurrency and retry, writes output:
import csv
import time
import random
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
from functools import lru_cache
API_KEY = "your_api_key"
BASE_URL = "https://ipintelligence.abstractapi.com/v1/"
CONCURRENCY = 25
MAX_RETRIES = 5
session = requests.Session()
def get_wait_time(headers: dict) -> float:
remaining = int(headers.get("X-RateLimit-Remaining", 1))
reset_ts = int(headers.get("X-RateLimit-Reset", 0))
if remaining == 0 and reset_ts:
return max(reset_ts - time.time(), 0) + 1
return 0
@lru_cache(maxsize=10_000)
def lookup_ip(ip: str) -> dict:
params = {"api_key": API_KEY, "ip_address": ip}
for attempt in range(MAX_RETRIES):
resp = session.get(BASE_URL, params=params)
if resp.status_code == 200:
return resp.json()
if resp.status_code == 429:
wait = get_wait_time(resp.headers)
if wait == 0:
wait = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait)
continue
resp.raise_for_status()
return {"ip_address": ip, "error": "max retries exceeded"}
def process(input_path: str, output_path: str):
with open(input_path) as f:
ips = list({row["ip"] for row in csv.DictReader(f)}) # dedupe
results = {}
with ThreadPoolExecutor(max_workers=CONCURRENCY) as executor:
futures = {executor.submit(lookup_ip, ip): ip for ip in ips}
for future in as_completed(futures):
ip = futures[future]
results[ip] = future.result()
fields = ["ip_address", "country", "country_code", "city", "asn",
"isp", "is_vpn", "is_proxy", "is_tor", "is_hosting", "risk_score"]
with open(output_path, "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fields, extrasaction="ignore")
writer.writeheader()
writer.writerows(results.values())
if __name__ == "__main__":
process("ips.csv", "enriched_ips.csv")
No frameworks. Handles deduplication, concurrency sizing, rate limit headers, exponential backoff, and LRU caching.
Snowflake: Python UDF
If your IP data lives in Snowflake, you can enrich it in-database without moving data out. Snowflake's Python UDFs run per-row, so add a result cache to avoid redundant requests for repeated IPs:
CREATE OR REPLACE FUNCTION enrich_ip(ip_address STRING)
RETURNS VARIANT
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
PACKAGES = ('requests')
HANDLER = 'run'
AS $$
import requests
import json
API_KEY = "your_api_key"
BASE_URL = "https://ipintelligence.abstractapi.com/v1/"
cache = {}
def run(ip_address):
if ip_address in cache:
return cache[ip_address]
try:
resp = requests.get(
BASE_URL,
params={"api_key": API_KEY, "ip_address": ip_address},
timeout=5
)
result = resp.json() if resp.status_code == 200 else {"error": resp.status_code}
except Exception as e:
result = {"error": str(e)}
cache[ip_address] = result
return result
$$;
Call it against a table column:
SELECT
ip,
enrich_ip(ip):country::STRING AS country,
enrich_ip(ip):asn::STRING AS asn,
enrich_ip(ip):is_vpn::BOOLEAN AS is_vpn,
enrich_ip(ip):risk_score::INT AS risk_score
FROM your_ip_table
LIMIT 1000;
For large tables, filter to distinct IPs first, enrich, then join back. Calling the UDF on millions of rows without deduplication will exhaust your request allowance quickly. See the full guide to IP geolocation in Snowflake for the production-ready pattern with a staging table and incremental refresh.
BigQuery: remote function
BigQuery doesn't support outbound HTTP calls from standard UDFs. The pattern here is a Remote Function backed by a Cloud Run or Cloud Functions endpoint that proxies requests to Abstract IP Intelligence.
Cloud Function (Python):
import functions_framework
import requests
API_KEY = "your_api_key"
BASE_URL = "https://ipintelligence.abstractapi.com/v1/"
@functions_framework.http
def enrich_ip(request):
calls = request.get_json()["calls"]
results = []
for call in calls:
ip = call[0]
try:
resp = requests.get(
BASE_URL,
params={"api_key": API_KEY, "ip_address": ip},
timeout=5
)
results.append(resp.json() if resp.status_code == 200 else None)
except Exception:
results.append(None)
return {"replies": results}
Register it as a BigQuery Remote Function:
CREATE OR REPLACE FUNCTION your_dataset.enrich_ip(ip STRING)
RETURNS JSON
REMOTE WITH CONNECTION `your-project.your-region.your-connection`
OPTIONS (endpoint = 'https://your-cloud-function-url');
Then call it like any other function:
SELECT
ip,
enrich_ip(ip).country AS country,
enrich_ip(ip).is_vpn AS is_vpn,
enrich_ip(ip).risk_score AS risk_score
FROM your_dataset.ip_events
WHERE DATE(event_time) = CURRENT_DATE();
BigQuery batches Remote Function calls automatically, so you don't manage concurrency. For very large tables, partition your query by date and run enrichment incrementally rather than scanning the full table each time.
Match the Method to the Volume
Decide volume first. Everything else follows.
Under 1 million requests per day: a real-time API with concurrency and caching covers you. You get fresh data, pay only for what you use, and skip any infrastructure overhead.
Between 1 million and 100 million: a batch endpoint removes concurrency management from your side. Submit a list, retrieve enriched output, move on.
Over 100 million: a self-hosted database is the only option that keeps unit costs manageable, with the understanding that you're trading data freshness for throughput.
Abstract IP Intelligence handles all three patterns with the same underlying dataset. VPN, proxy, Tor, and risk score are included in every response by default. The same fields and the same response schema work whether you're calling one IP from a Python script, enriching a Snowflake table with a UDF, or running a nightly BigQuery job.
Try IP Intelligence!
