

Every time you visit a website—whether you’re shopping online, checking the weather, or reading this article—your browser builds an invisible yet powerful structure behind the scenes. This structure is called the DOM, and it’s the key to creating interactive, responsive websites.
In this guide, we’ll break down what the DOM is, how it works, and why it’s so important for developers. We’ll also explore how the DOM connects with APIs to display real-world data and bring static pages to life. By the end, you’ll have a solid understanding of how tools like AbstractAPI help developers transform ordinary web pages into dynamic, user-driven experiences.
🔎 What Is the DOM?
The Document Object Model (DOM) is a programming interface that represents an HTML or XML document as a structured tree. Think of it as a blueprint of your web page—each HTML element becomes a node in this tree, making it easier for scripts like JavaScript to access and update parts of the page in real time.
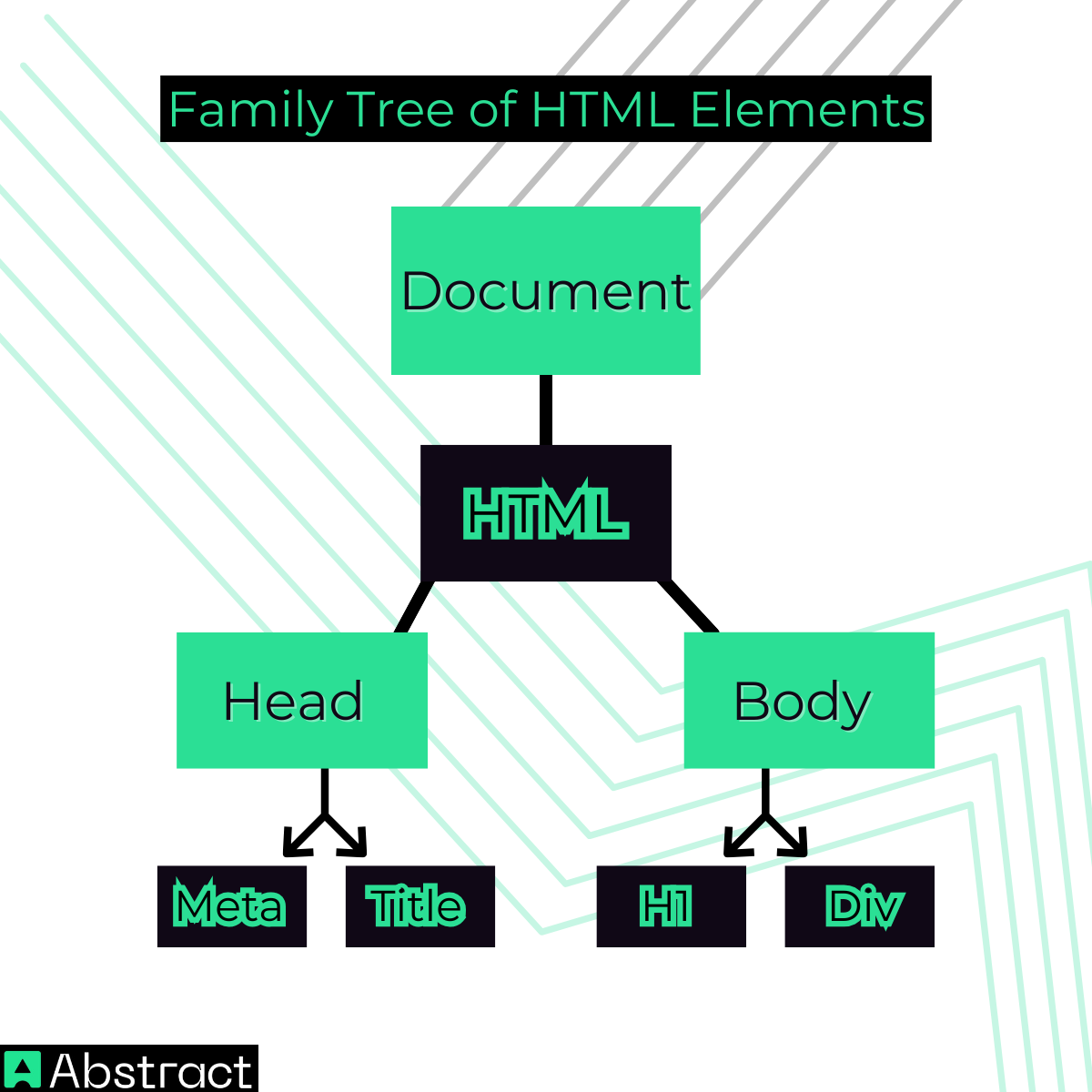
DOM Analogy: A Family Tree of HTML Elements 👨👩👧👦
Imagine a family tree, where every person (or node) is connected in a hierarchy. At the top, there’s a grandparent (the <html> element), followed by parents (<head>, <body>), and then children like <div>, <h1>, <p>, and more. The DOM works in much the same way: each element has a position and relationship within the document, and JavaScript can “talk” to them individually.
⚙️ How Does the DOM Work?
To understand how the DOM functions, let’s start from the beginning—when a web page loads.
When you type a URL into your browser and hit enter, the browser sends a request to a server. The server responds with an HTML document, which is essentially a structured text file containing the content and layout instructions for the page.
As the browser receives this HTML, it parses (reads and processes) the code line by line. During this process, it creates a tree-like structure in memory called the Document Object Model (DOM). This structure represents every element in the HTML—such as <div>, <h1>, <p>, or <img>—as a node in a hierarchy.
🧩 Types of Nodes in the DOM
Each part of the HTML page is represented in the DOM as a specific type of node:
- Document Node: The root node from which all other nodes branch out.
- Element Nodes: Represent HTML elements like <body>, <ul>, or <a>.
- Attribute Nodes: Represent the attributes of elements, like href in a link or src in an image.
- Text Nodes: Represent the actual text inside elements, such as the text between <p>This is text</p>.
🔁 A Live Representation
It’s important to note that the DOM is live, meaning that it reflects the current state of the page at any given time. If JavaScript adds a new element to the page or modifies content, the DOM updates instantly to reflect those changes—even without reloading the page.
This dynamic nature is what makes things like dropdown menus, modals, and form validations possible.
💬 Real-World Analogy
Think of your HTML as the blueprint for a building, and the DOM as the interactive 3D model of that building. You can walk around, open doors, rearrange furniture, and add new rooms—all using JavaScript as your toolset.
💡 Manipulating the DOM with JavaScript
JavaScript is the main tool developers use to modify the DOM. Here's how you can use JavaScript to interact with different parts of a webpage:

✅ Selecting Elements:
const heading = document.getElementById("main-title");
const paragraph = document.querySelector(".description");
📝 Changing Content
heading.textContent = "Welcome to My Site!";
paragraph.innerHTML = "<strong>This is bold text inside a paragraph.</strong>";
🎨 Modifying Styles
heading.style.color = "royalblue";
paragraph.style.backgroundColor = "#f0f0f0";
➕ Adding New Elements
const newItem = document.createElement("li");
newItem.textContent = "New List Item";
document.querySelector("ul").appendChild(newItem);
These are foundational steps in making your website feel responsive and alive. But how do you make it smart—like showing a user’s city, validating an email, or pulling the latest news?
🔗 The DOM Alone Isn’t Enough: Enter APIs
While the DOM gives you control over a webpage’s structure and content, it doesn’t know anything about the world outside your HTML file. If you want to show live data—like the current temperature, a user’s location, or real-time search results—you need to bring in external information.
This is where APIs (Application Programming Interfaces) come in. APIs let your web application communicate with outside services to fetch and send data. Once you have that data, you can use the DOM to display it dynamically.
Think of the DOM as your canvas, and the API as your paintbrush. One shapes the layout, the other adds the details. 🎨
🌍 Bringing the DOM to Life with AbstractAPI
Let’s walk through a practical example using AbstractAPI’s IP Geolocation API.
📍 Use Case: Show the User’s Location on Your Website
Suppose you want your webpage to display where the visitor is browsing from. You can fetch that data from AbstractAPI and then insert it into your page using DOM methods.
👨💻 Sample Code:
<div id="location">Loading location...</div>
<script>
fetch("https://ipgeolocation.abstractapi.com/v1/?api_key=your_api_key")
.then(response => response.json())
.then(data => {
const locationDiv = document.getElementById("location");
locationDiv.innerHTML = `🌍 You are visiting from <strong>${data.city}, ${data.country}</strong>`;
})
.catch(error => {
console.error("Error fetching location data:", error);
});
</script>
🔄 What’s Happening Here?
- The browser sends a request to AbstractAPI’s IP Geolocation endpoint.
- It receives a response in JSON format containing the user's city, country, and more.
- JavaScript selects the <div> with id="location" using getElementById.
- It updates the content of the <div> using innerHTML.
The result? Your previously static HTML page now displays personalized data—powered by an API and shown using the DOM.
👉 Explore more APIs you can use with the DOM in our API Toolbox.
🧠 Conclusion: The DOM + API = Dynamic Web
The Document Object Model is the essential building block of interactive web pages. It allows JavaScript to access and modify HTML content in real time. But to truly engage users with personalized or real-time content, you’ll need to combine the DOM with APIs.
APIs provide the live data. The DOM displays it. Together, they power modern web applications—from email validation to weather updates to IP-based personalization.
✨ Tools like AbstractAPI make it simple to fetch reliable data, while the DOM helps you present it smoothly. Master both, and you're well on your way to becoming a frontend development pro.
🔗 Learn More
